
- 진행 날짜 - 2021.11.15 pm 16:00 ~ 2021.11.17 am 10:00
- 과제 필수 포함 사항
✔️ 확인 사항
- ORM 사용 필수
- 데이터베이스는 SQLite로 구현
- secret key, api key 등을 레포지토리에 올리지 않도록 유의
- README.md 에 관련 설명 명시 필요
✔️ 도전 과제: 스스로에게도 도움이 되는 내용 + 추가 가산점
- 배포하여 웹에서 사용 할 수 있도록 제공
- 임상정보 검색 API 제공
✔️ 과제 안내
다음 사항들을 충족하는 서비스를 구현해주세요.
- 임상정보를 수집하는 batch task
- 참고: https://www.data.go.kr/data/3074271/fileData.do#/API 목록/GETuddi%3Acfc19dda-6f75-4c57-86a8-bb9c8b103887
- 수집한 임상정보에 대한 API
- 특정 임상정보 읽기(키 값은 자유)
- 수집한 임상정보 리스트 API
- 최근 일주일내에 업데이트(변경사항이 있는) 된 임상정보 리스트
- pagination 기능
- 최근 일주일내에 업데이트(변경사항이 있는) 된 임상정보 리스트
- Test 구현시 가산점이 있습니다.
- 13팀 과제 Github 리포지토리
GitHub - preOnboarding-Team13/Assignment-5-humanscape: 휴먼스케이프!
휴먼스케이프! Contribute to preOnboarding-Team13/Assignment-5-humanscape development by creating an account on GitHub.
github.com
🏫 사용한 프레임워크 & 라이브러리
- Nest JS
- config
- supertest
- typeorm sqlite3
- class-validator & class-transformer
- lodash
- sqlite3
- schedule
💯 구현 목록
임상 정보
- ✅ 업데이트된 임상정보 리스트 API
- ✅ 임상정보를 수집하는 batch task
- ✅ 특정 임상 정보 읽기 API
테스트 코드
- ✅ Unit Test
추가 고려 사항
- ✖️ 임상정보 검색 API
📋 Database Modeling
💭 Project Review
프리온보딩 백엔드 코스 5차 과제로 헬스케어 서비스를 제공하고 있는 휴먼스케이프 기업의 과제를 진행하였습니다. 이번 과제는 필요한 API도 조회 기능이 있는 API가 전부였고, 특이하게도 임상정보를 수집하는 batch task를 구현해야 했습니다. 참고 링크를 들어가 보시면 공공데이터 포털의 질병관리청의 임상정보 데이터란으로 이동하게 됩니다. 공공데이터 포털에서 제공해주는 API를 사용하여 데이터를 확인해 보니 각각의 임상정보 데이터들이 JSON 형식으로 제공되고 있었습니다. 다만, 원래 링크가 제공해주는 데이터가 너무 부족하여 다른 임상정보 데이터를 활용하여 프로젝트를 하기로 하였습니다.
💬 Batch Scheduler를 위한 데이터 베이스 설계를 하자
팀원 모두가 batch task를 구현해본 적이 없었기 때문에 어떻게 데이터베이스 구조를 만들어야 할지 많은 의견이 오고 갔습니다. 우선 일괄적으로 데이터를 가지고 올 때 테이블에 어떻게 데이터를 넣을 것인지 의논하였으며, 매번 새로 데이터를 가지고 올 때마다 DB를 전부 싹 지우고 새로 넣는다라는 의견과 데이터를 새로 가지고 올 때 기존 데이터를 업데이트하고, 새로운 데이터는 새로 만든다라는 의견이 충돌하였으나, 후자의 의견을 따르는 것으로 맞춰졌습니다.

다음으로는 데이터베이스 모델링 작업을 진행하였습니다. 처음에는 임상정보 데이터가 제공해주는 json의 key값에 맞춰서 칼럼을 생성하여 데이터를 저장하려고 했습니다. 그런데 임상정보 데이터의 각 json의 key값을 칼럼화 하여 데이터를 넣는 작업은 해당 임상정보 데이터의 json이 많으면 많을수록 많은 Row가 생겼고, 수정된 임상정보 데이터를 Scheduler가 읽어서 비교하려면 모든 Row를 대상으로 비교를 해야 했습니다.
이것보다 더 좋은 방법이 없을까 고민하던 중 임상정보 데이터 json 전체를 json 객체를 String 객체로 변환시켜주는 JSON.stringify()를 사용하여 통째로 칼럼에다가 넣어주는 방법을 사용해보는 것은 어떻겠냐고 팀원분의 의견을 주셔서 해당 방법을 사용해보기로 했습니다. 일단 sqlite에서 제공해주는 데이터 타입 중에서 해당 임상정보 데이터 전체를 저장할 수 있을 정도로 큰 것이 있는지 찾아보아야 했습니다. 없다면 이 방법은 쓰나 마나일 테니까요.
찾아보니 clob이라는 대용량 텍스트 데이터를 저장할 수 있는 데이터 타입이 존재했고, 해당 타입이 저장할 수 있는 최대 크기는 무려 약 4GB 정도였습니다. 저희가 사용한 임상정보 데이터는 6000개 정도의 데이터가 존재하고 있었는데, 글자 10글자를 저장하는데 필요한 공간이 20byte 정도 이기 때문에 이것을 기준으로 계산해보면 대략 하나의 Row의 data 칼럼은 약 1억의 데이터를 문자열로 변환해 저장할 수 있었습니다. 그리고 Batch Scheduler가 데이터베이스의 각 Row와 비교하지 않아도 하나의 Row의 data 칼럼이 가지고 있는 문자열 데이터와 새로 들어오는 문자열 데이터만 비교하면 됐기 때문에 작업을 편하게 할 수 있었습니다. 생각지도 못한 방법인 데다가, 시도해 본 적이 없는 방법이었어서 이해하기 어려웠지만 금세 적응할 수 있었답니다.

이 새로운 방법의 경우에는 장점이 여럿 있었는데요. 일단 처음에 저희가 시도했던 방법인 json의 key값을 칼럼으로 하여 저장하는 경우에는 Batch Schedular가 읽는 임상정보 데이터의 json 수가 6000개 정도라고 하면 하루마다 약 6000개의 데이터가 생깁니다. 때문에 금일과 전날을 비교하려고 할 때는 Row를 돌면서 이전날인지 체크하고 비교하는 어려운 작업을 해야 합니다.
하지만 저희가 사용한 방법은 하루마다 하나의 Row가 생기며 1년에는 고작 365개의 Row밖에 생기지 않습니다. 또한 비교도 문자열 비교를 사용하기 때문에 각 Row별 비교가 쉽고, 업데이트 여부 파악과 업데이트 전후 데이터 관리를 용이하게 할 수 있습니다.
이러한 방법을 사용해서 만들어진 저희의 데이터베이스를 Git 형식으로 예를 들어 설명하게 되면 밑의 그림처럼 설명할 수 있을 것 같습니다. trials 테이블은 매일 Batch Scheduler가 돌며 읽은 데이터가 저장되고, updated Trials 테이블은 trials 테이블에 저장된 전날 데이터와 비교했을 때 수정된 데이터가 저장됩니다. 마지막으로 updated Trials Bundles 테이블은 7일간 업데이트 내역을 저장하게 됩니다. 이 작업들은 Batch Scheduler가 사람들이 사용하지 않는 시간대인 새벽 5시에 이루어지도록 구현하였습니다.
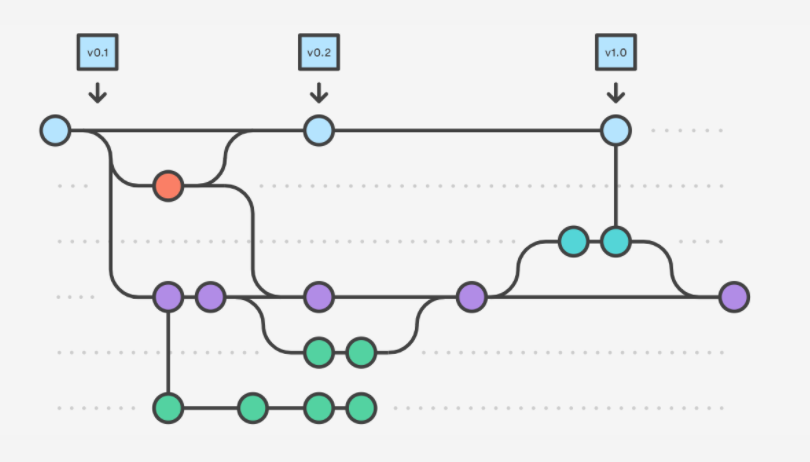
💬 임상정보 Open API 조회
임상정보 Open API는 페이지 방식을 사용해서 조회되기 때문에 한 번에 가져올 수 있는 데이터의 양이 제한되어 있습니다. 총 6000개 정도의 데이터가 있다고 가정할 경우, Batch Scheduler가 1 페이당 50개씩 데이터를 가져온다고 할 때 못해도 120번 이상의 반복 작업을 수행해야 합니다. 데이터가 많으면 많을수록 반복 회수가 당연히 늘어날 것이고 Batch Scheduler가 수행되는 시간이 증가하게 됩니다. 그래서 좀 더 빠르게 가져오기 위해서 for 방식을 사용해야 할지 Promise.all 방식을 사용해야 할지 해당 로직을 구현했던 팀원분이 많은 고민을 했다고 하셨습니다.
그렇게 팀원분이 고민한 결과 for 방식으로 Open API를 사용하도록 구현하셨습니다. promise.all 방식을 사용해서 병렬로 해당 Open API를 요청하게 되면 데이터가 6000개라고 할 때, 120번의 요청을 병렬로 수행하게 되기 때문에 Open API 트래픽이 과부하 되거나, Ping of Death 공격으로 오인당하여 IP 차단을 당할 수도 있을 것 같아서 for방식을 사용했다고 하네요.
// 최초 요청
let allData = information.data[dataKey];
const totalCount = information.data[config.params.totalCount];
const pageSize = information.data[config.params.numOfRows];
const maxPage = Math.ceil(totalCount / pageSize);
// 2 page ~ maxPage
for (let pageNo = 2; pageNo <= maxPage; pageNo++) {
config.params.pageNo = pageNo;
information = await lastValueFrom(
this.httpService.get(url, config)
);
const items = information.data[dataKey];
allData = [...allData, ...items];
}
💬 TypeOrm Cursor Pagination 재도전
지난번 프로젝트에서 typeorm cursor pagination 라이브러리를 사용해서 코드가 엉망이 된 것을 보고 직접 구현하겠다고 마음먹었는데 그걸 이번 프로젝트에서 하게 될 줄은 몰랐습니다. 그래서 요번에는 라이브러리 사용하지 않고 cursor pagination을 구현해 보았습니다.
이번 pagination을 구현하기 위해 총 데이터 수를 가져오는 쿼리, 현재 페이지 데이터, 양끝의 Row를 기준으로 이전과 이후의 데이터가 있는지 검증하는 쿼리를 만들었습니다. 양끝의 Row를 기준으로 이전과 이후 데이터가 있는지 검증하는 쿼리가 필요했던 이유는, 다음 페이지나 혹은 해당 페이지 이전의 페이지에 데이터가 존재하지 않는다면 cursor를 생성하면 안 됐기 때문입니다. 직접 만드려니까 코드가 조금 지저분해져서 실행했을 때의 SQL문을 보여드리겠습니다.
SELECT count(value) as count
FROM updatedTrialBundles, json_each(weekly)
WHERE DATE(createdAt) ='2021-11-16'
SELECT value
FROM updatedTrialBundles, json_each(weekly)
WHERE DATE(createdAt) ='2021-11-16'ORDER BY json_extract(json_each.value, '$.trial_id') DESC
LIMIT 1
SELECT EXISTS (
SELECT value
FROM updatedTrialBundles, json_each(weekly)
WHERE json_extract(json_each.value, '$.trial_id') <'KCT0006764'
AND DATE(createdAt) ='2021-11-16') AS success
SELECT EXISTS (
SELECT value
FROM updatedTrialBundles, json_each(weekly)
WHERE json_extract(json_each.value, '$.trial_id') >'KCT0006764'
AND DATE(createdAt) ='2021-11-16') AS success
👩💻반성점 OR 다음 프로젝트부터 고치고 싶은 것
이번 프로젝트에는 조금 생소한 방식으로 데이터베이스 설계를 하고 적용하였으며, 페이징 쿼리를 라이브러리 없이 만드는 작업을 했습니다. 제가 작업을 한 부분에서 가장 마음에 안 드는 부분은 페이징 쿼리 부분입니다. select를 4번 돌게 하지 말고 서브 쿼리를 잘 사용했으면 더 적은 수의 쿼리로 해결했을 것 같다는 아쉬움이 남습니다. 다음 프로젝트에서는 쿼리에 더 많은 신경을 쓰고, 깔끔한 코드를 만들기 위해 노력을 해야 할 것 같다고 생각했습니다.
'프리온보딩 백엔드 > TIL(Today I Learned)' 카테고리의 다른 글
| [Assignment 7] Cardoc(카닥) TIL (0) | 2021.11.30 |
|---|---|
| [Assignment 6] Deer(디어) TIL (3) | 2021.11.24 |
| [Assignment 4] 8PERCENT(8퍼센트) TIL (0) | 2021.11.14 |
| [Assignment 3] RED BRICK(레드브릭) TIL (0) | 2021.11.11 |
| [Assignment 2] MAPIA COMPANY(마피아 컴퍼니) TIL (0) | 2021.11.07 |



