
- 진행 날짜 - 2021.11.11 pm 17:00 ~ 2021.11.13 am 10:00
- 과제 필수 포함 사항
✔️ API 목록
거래내역 조회 API
- 입금 API
- 출금 API
✔️ 주요 고려 사항은 다음과 같습니다.
- 계좌의 잔액을 별도로 관리해야 하며, 계좌의 잔액과 거래내역의 잔액의 무결성의 보장
- DB를 설계 할때 각 칼럼의 타입과 제약
✔️ 구현하지 않아도 되는 부분은 다음과 같습니다.
- 문제와 관련되지 않은 부가적인 정보. 예를 들어 사용자 테이블의 이메일, 주소, 성별 등
- 프론트앤드 관련 부분
✔️ 제약사항은 다음과 같습니다.
- (8퍼센트가 직접 로컬에서 실행하여 테스트를 원하는 경우를 위해) 테스트의 편의성을 위해 mysql, postgresql 대신 sqllite를 사용해 주세요.
✔️ 상세 설명
1) 거래내역 조회 API
거래내역 API는 다음을 만족해야 합니다.
- 계좌의 소유주만 요청 할 수 있어야 합니다.
- 거래일시에 대한 필터링이 가능해야 합니다.
- 출금, 입금만 선택해서 필터링을 할 수 있어야 합니다.
- Pagination이 필요 합니다.
- 다음 사항이 응답에 포함되어야 합니다.
- 거래일시
- 거래금액
- 잔액
- 거래종류 (출금/입금)
- 적요
2) 입금 API
입금 API는 다음을 만족해야 합니다.
- 계좌의 소유주만 요청 할 수 있어야 합니다.
3) 출금 API
출금 API는 다음을 만족해야 합니다.
- 계좌의 소유주만 요청 할 수 있어야 합니다.
- 계좌의 잔액내에서만 출금 할 수 있어야 합니다. 잔액을 넘어선 출금 요청에 대해서는 적절한 에러처리가 되어야 합니다.
4) 가산점
다음의 경우 가산점이 있습니다.
- Unit test의 구현
- Functional Test 의 구현 (입금, 조회, 출금에 대한 시나리오 테스트)
- 거래내역이 1억건을 넘어갈 때에 대한 고려
- 이를 고려하여 어떤 설계를 추가하셨는지를 README에 남겨 주세요.
- 13팀 과제 Github 리포지토리
GitHub - preOnboarding-Team13/Assignment-4-8percent
Contribute to preOnboarding-Team13/Assignment-4-8percent development by creating an account on GitHub.
github.com
🏫 사용한 프레임워크 & 라이브러리
- Nest JS
- config
- supertest
- class-validator & class-transformer
- passport-local & passport-jwt
- typeorm mysql2 & sqlite3
- morgan
- swagger
- bcrypt
- typeorm-seeding
💯 구현 목록
- User✅ 로그인
- ✅ 회원가입
- 계좌 관리✅ 계좌 삭제
- ✅ 계좌 생성
- 거래 및 조회
- 입금/ 출금/ 전체 내역 조회
- 시작날짜 ~ 종료날짜 검색
- 최소금액 ~ 최대금액 검색
- 적요 검색
- ✅ 출금 API
- ✅ 거래내역 조회 API
- 테스트 코드✖️ Functional Test (입금, 조회, 출금에 대한 시나리오 테스트)
- ✅ Unit Test
- 추가 고려 사항
- ✅ 거래 내역이 1억건 이상일 때에 대한 고려
📋 Database Modeling
💭 Project Review
프리온보딩 백엔드 코스 4차 과제로 8퍼센트 기업에서 주신 과제를 진행하였습니다. P2P금융 스타트업이라 그런지 과제부터가 "계좌 거래 API"를 구현하는 것이었습니다. 다른 과제들처럼 CRUD에 특별한 점은 없었지만 고려 사항에 DB를 설계할 때 각 칼럼의 타입과 제약을 걸고, 거래내역이 1억 건을 넘어갈 때에 대한 고려를 해주면 좋겠다고 해주셨습니다. 1차 과제로 했던 AIMMO과제에도 비슷한 조건이 있었는데 그때는 시간이 없어서 진행을 못했던 것이 아쉽게 남았습니다. 그래서 요번에는 DB 설계를 좀 더 꼼꼼히 하고 성능 테스트도 해보기로 했습니다.
💬 데이터 베이스 설계를 하자
저희 팀의 ERD를 보시면 간단하게 3개의 테이블로 구성된 것을 확인하실 수 있습니다. 처음에는 입/출금 내역을 관리하는 history 테이블을 입금 내역, 출금 내역을 관리하는 각각의 테이블로 쪼개서 총 4개의 테이블을 만드려고 했습니다. 왜냐하면 이렇게 테이블을 분리해두면 합쳤을 때보다 입금, 출금 각각의 내역을 찾으려고 할 때 좀 더 좋은 성능을 보여주기 때문입니다. 하지만 분리해두면 입금, 출금 내역 모두의 내역을 한꺼번에 찾으려고 할 때 서브 쿼리가 걸리기 때문에 아무래도 합쳤을 때의 테이블보다는 좋지 않은 성능을 보여주게 됩니다. 데이터가 적을 때는 그 차이가 미미하지만 데이터가 많아지면 많아질수록 엄청 커지게 되죠. 저희 팀은 오랜 토론 끝에 합치든, 합치지 않든 성능은 거기서 거기일 것이다 라는 결론에 도달했고 합쳐서 작업하기로 하였습니다.
데이터베이스 데이터 타입을 설정할 때 각각 해당 칼럼에 적절한 크기를 정해서 설정을 해두었습니다. varchar의 경우 가변 길이 문자열을 저장하기 때문에 필요한 만큼만 공간을 사용해서 크기를 지정하는 게 무의미해 보일 수도 있지만, 아무래도 관계형 데이터베이스에서는 내부적으로 값을 저장할 때 고정 크기의 메모리를 할당하기 때문에 크기를 크게 설정하면 메모리를 의도치 않게 더 많이 사용할 수도 있습니다. 그래서 varchar의 경우에도 전부 데이터 크기를 지정해두었습니다.
계좌의 잔액의 경우 INT 형이 아니라 decimal 형으로 지정해둔 이유는 시스템의 확장 가능성 때문이었습니다. 원화만 사용할 것이라면 소수점이 필요하지 않기 때문에 INT 형을 사용해도 상관없으나, 해외로 서비스를 확장하거나 하는 등 소수점이 필요한 상황이 있다면 INT형으로는 처리하기 힘들기 때문이었습니다. 그래서 decimal 형태로 설정하여 이한 서비스의 확장 가능성에 대비하였습니다.
💬 도메인 주도 설계
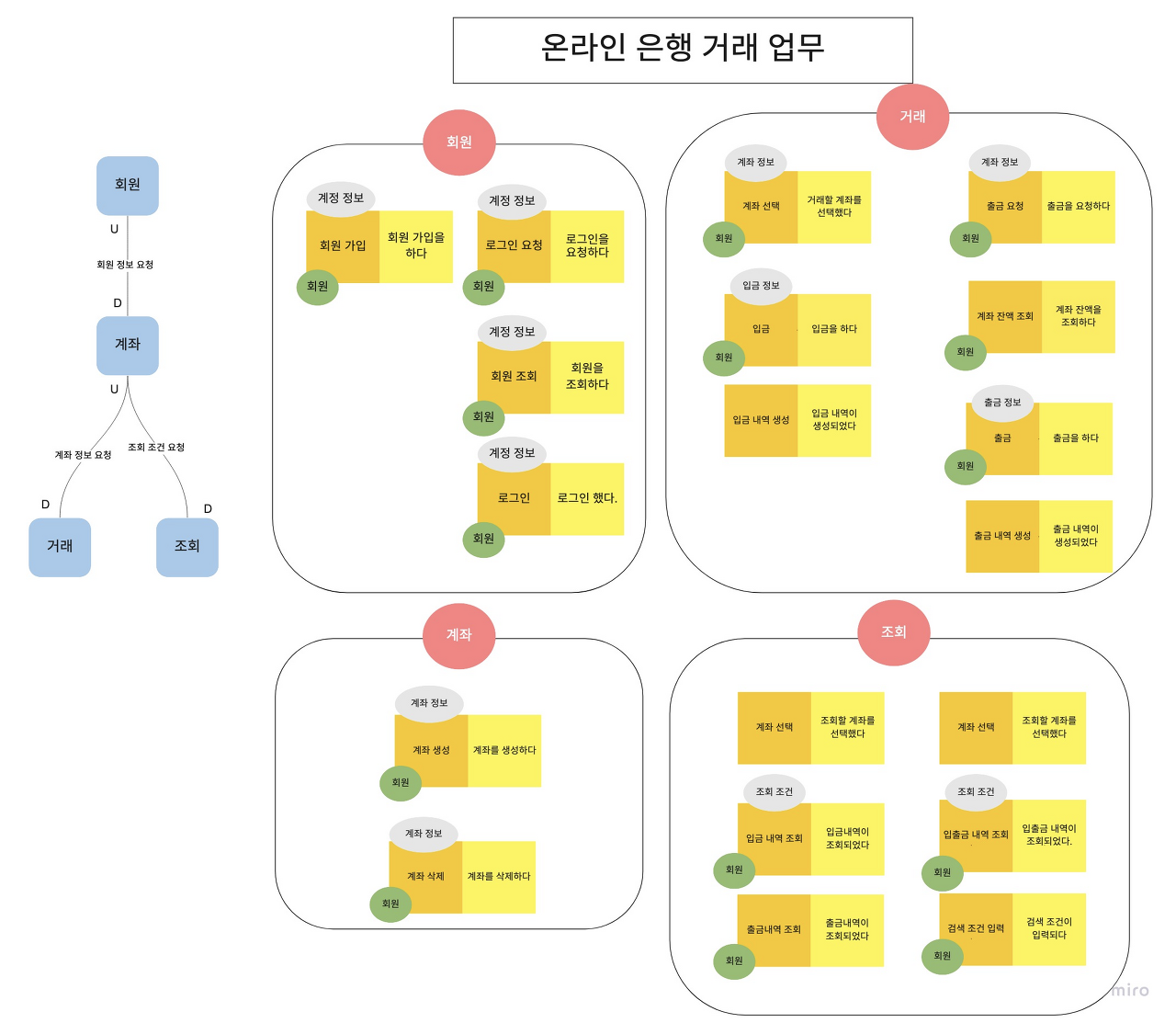
도메인이란 소프트웨어로 해결하고자 하는 문제 영역, 요구사항, 업무의 집합 등을 의미하는 단어입니다. 도메인 주도 설계는 이러한 도메인 위주로 설계하며 기존의 데이터에 종속적인 어플리케이션을 개발하며 발생하는 모델링과 개발 간 불일치를 해소하기 위해 나타난 방법입니다. 요번 프로젝트에서 도메인 주도 설계를 해보자는 의견이 나와서 팀원 전체가 다 같이 참여해보기로 하였습니다. 물론 처음 하는 설계 방법이라 하는 것이 쉽지 않았습니다. 도메인 주도 설계 방법론을 소개하는 블로그 글은 많았는데 이해하기 어려운 글들이 많았어서, 어차피 설계하는 정공법이 존재하지 않는다면 우리 팀원들의 생각대로 만들어보자고 해서 설계를 시작하였습니다.
우선 해당 프로젝트에서 필요한 동작들을 정해나가기 시작했습니다. 회원 가입을 한다던가, 입금요청을 한다던가를 말이죠. 동작을 정의한 다음에는 해당 동작들을 하나의 도메인으로 묶어나가기 시작했습니다. 회원 가입의 경우에는 회원과 관련 있기 때문에 회원 도메인에 넣고, 입/출금 등의 동작들은 거래 도메인으로 묶어나갔습니다. 그다음에는 각각의 동작에 필요한 정보 혹은 조건들을 작성해 나갔습니다. 예를 들면 계좌 선택 시에는 반드시 회원이 로그인되어있어야 하고, 계좌 정보를 입력받아야 하는 조건이 필요합니다. 마지막으로는 전체 도메인 간의 흐름을 정의하였습니다.
처음 해보는 방식이라 미숙했지만 완성되고 나니 의외로 그럴듯 해보입니다. 이렇게 만들어두고 프로젝트를 진행하니 프로젝트의 큰 흐름을 이해하기가 훨씬 더 쉬웠습니다.
💬 TypeOrm Seeding
거래내역이 1억 건 넘어갈 때의 성능을 확실히 하기 위해서는 데이터베이스에 그만큼의 데이터가 들어있어야 합니다. 그런데 어떤 바보가 INSERT 문으로 그걸 다 하나하나씩 넣고 있겠어요? 그래서 저희 팀은 TypeOrm Seeding 라이브러리를 사용해서 데이터를 생성해서 넣어주기로 했습니다.
TypeOrm Seeding 라이브러리는 각 엔티티마다 factory 코드를 작성해주면 해당 코드에 맞게 데이터를 마구마구 생성해서 데이터베이스에 넣어줍니다. factory 코드에서 가짜 데이터를 만들기 위해 faker 라이브러리를 사용하려고 했는데, datatype이 undefined라는 오류가 계속 발생해서 faker를 사용하지 않고 생성하였습니다.
하지만 이렇게 생성한 데이터들에 한 가지 문제가 발생하였습니다. 이상하게 history 부분의 외래 키에는 accountNum가 들어가지만 account의 외래 키에는 null이 들어갔습니다. 디버깅 툴을 확인해서 값을 확인해봤는데 정상적으로 들어감에도 불구하고, account의 외래 키에 user 정보가 누락돼서 들어갔습니다.
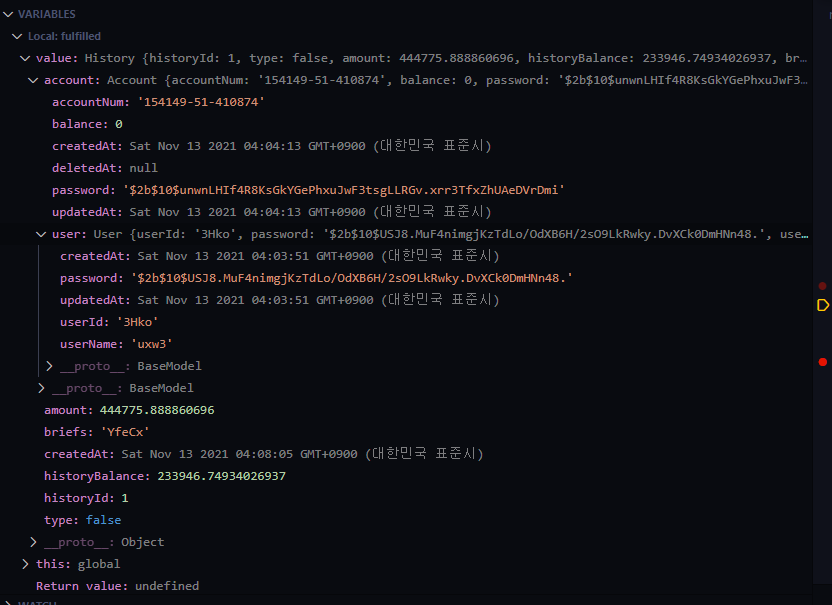
user - account - history가 모두 연결된 온전한 seed를 만드는 데는 실패했지만, 이렇게 데이터를 만든 이유는 다음에 있을 페이징의 성능 향상을 눈으로 확인하기 위함이었습니다. 그래서 일단은 account와 history만 연결된 seed 데이터를 34650건 생성하였습니다. 원래는 100만 건을 넣으려고 했으나 3만 건 정도 만드는데도 20분이 걸렸기 때문에....
TypeOrm seeding 관련 코드는 저희 팀 리포지토리의 typeorm-seeding 브랜치에 있습니다.
💬 TypeOrm Cursor Pagination
이번 프로젝트에서는 저번부터 꼭 해보고 싶었던 페이징 성능 향상에 도전해보기로 했습니다. 맨날 같은 페이징 방식만 쓰면 재미없잖아요?
관계형 데이터베이스에서 페이징의 성능 향상을 하는 방법은 다양하지만 그중에서도 가장 많이 사용하는 방법인 Cursor pagination 방법을 사용해서 성능 향상을 했습니다. 그런데 우선 어느 부분에서 성능 향상이 됐는지 눈으로 봐야지 알 수 있을 것 같아서 기존에 TypeOrm에서 지원해주는 페이징 방식인 limit offset pagination 방식과 비교해보도록 하겠습니다.
다음의 코드는 limit와 offset을 사용한 TypeOrm createQueryBuilder 코드입니다.
const page = pageNum * 10 || 0;
const historyQuery = await this.createQueryBuilder("h")
.select("h.type", "거래종류")
.addSelect("h.amount", "사용 금액")
.addSelect("h.historyBalance", "거래후 잔액")
.addSelect("h.brief", "적요")
.addSelect("h.createdAt", "거래일시")
.innerJoin(Account, "a", "a.accountNum = h.accountNum");
if (type === typeOptions.deposit) historyQuery.where("h.type = TRUE");
if (type === typeOptions.withdraw) historyQuery.where("h.type = FALSE");
if (type === typeOptions.all)
historyQuery.where("h.type = TRUE OR h.type = FALSE");
historyQuery.andWhere("h.accountNum = :accountNum", {
accountNum: accountNum
});
if (startDate != undefined && endDate != undefined)
historyQuery.andWhere(
"h.createdAt BETWEEN :startDate AND :endDate",
{
startDate: startDate,
endDate: endDate
}
);
if (brief != undefined)
historyQuery.andWhere("h.brief = :brief", { brief: brief });
if (minAmount != 0 && maxAmount != 0)
historyQuery.andWhere(
"h.createdAt BETWEEN :minAmount AND :maxAmount",
{
minAmount: minAmount,
maxAmount: maxAmount
}
);
historyQuery.offset(page);
historyQuery.limit(10);
return historyQuery.getRawMany();
위의 코드에서 자잘 자잘한 조건을 제외하고 관계형 데이터베이스로 옮기면 다음의 쿼리가 완성됩니다.
SELECT
h.historyId as 'ID',
h.type as '거래종류',
h.amount as '사용 금액',
h.historyBalance as '거래후 잔액',
h.briefs as '적요',
h.createdAt as '거래일시'
FROM
history h,
account a
where
a.accountNum = h.accountNum
order by h.historyId DESC
limit 10
offset 0;
현재 데이터베이스에는 아까 전에 소개해드린 TypeOrm Seeding을 사용해서 미리 34650건의 입/출금 내역 데이터를 넣어두었습니다. 보통 내역 데이터는 가장 밑에 있는 내역이 최신 데이터이기 때문에 DESC 정렬을 한 후, 몇 ms가 걸리는지 확인해보았습니다. 확인 결과 상위 10행 (34650 ~ 34640)의 데이터를 가지고 오는데 18ms의 시간이 걸렸습니다.

그럼 가장 밑에 있는 데이터를 조회하면 몇 ms가 걸리게 될까요? 확인 결과 최하위 10행 (10 ~ 0)의 데이터를 가지고 오는데 37ms의 시간이 걸렸습니다.

그다음 하위 10행의 데이터를 가지고 오는데 36ms의 시간이 걸렸습니다. 보시다시피 최상위 데이터와 최하위 데이터를 가지고 오는 시간은 약 20ms 정도의 차이가 발생합니다. limit offset pagination 기법을 사용했을 때 상위 데이터와 하위 데이터를 가지고 오는데 이러한 시간 차이가 나는 이유는 모든 행을 읽어가다가 limit 만큼의 행만 읽고 버리기 때문입니다.
즉, limit 10 offset 34640의 경우에는 내가 필요한 건 최하위 10건이지만 실제로는 34650건을 모두 읽고 그중 10행을 제외한 나머지를 버리게 되는 것이죠.

그렇다면 cursor pagination은 어떨까요? 저희 팀이 사용한 cursor pagination 기법은 cursor라는 기준값을 사용해서 페이징을 하는 방식입니다. 라이브러리를 사용하지 않아도 구현할 수 있지만, 찾아보니 typeorm-cursor-pagination이라는 라이브러리가 있어서 사용해보기로 하였습니다. 다음의 코드는 typeorm-cursor-pagination 라이브러리를 사용해서 cursor pagination 기법을 사용한 TypeOrm createQueryBuilder 코드입니다.
const historyQuery = await this.createQueryBuilder("h").innerJoin(
Account,
"a",
"a.accountNum = h.accountNum"
);
if (query.type === typeOptions.deposit)
historyQuery.where("h.type = TRUE");
if (query.type === typeOptions.withdraw)
historyQuery.where("h.type = FALSE");
if (query.type === typeOptions.all)
historyQuery.where("h.type = TRUE OR h.type = FALSE");
if (query.after != undefined) {
historyQuery.andWhere("h.historyId < :historyId", {
historyId: this.cursorDecode(query.after)
});
}
if (query.before != undefined) {
historyQuery.andWhere("h.historyId > :historyId", {
historyId: this.cursorDecode(query.before)
});
}
historyQuery.andWhere("h.accountNum = :accountNum", {
accountNum: query.accountNum
});
if (query.startDate != undefined && query.endDate != undefined)
historyQuery.andWhere(
"h.createdAt BETWEEN :startDate AND :endDate",
{
startDate: query.startDate,
endDate: query.endDate
}
);
if (query.briefs != undefined)
historyQuery.andWhere("h.briefs = :briefs", {
briefs: query.briefs
});
if (query.minAmount != 0 && query.maxAmount != 0)
historyQuery.andWhere(
"h.createdAt BETWEEN :minAmount AND :maxAmount",
{
minAmount: query.minAmount,
maxAmount: query.maxAmount
}
);
historyQuery.orderBy("h.historyId", "DESC");
historyQuery.limit(query.limit);
if (query.after === undefined && query.before === undefined) {
const paginator = buildPaginator({
entity: History,
alias: "h",
paginationKeys: ["historyId"],
query: {
limit: query.limit,
order: "DESC"
}
});
const { data, cursor } = await paginator.paginate(historyQuery);
return { data, cursor };
코드를 보시면 알 수 있듯이... 코드가 좀 그렇습니다. 저희 팀이 사용한 typeorm-cursor-pagination의 라이브러리 util 파일을 보니 cursor를 base64 방식을 사용하여 암호화하고, 그것을 복호화하면서 페이징을 수행하고 있었습니다. 그런데 해당 라이브러리가 암호화된 cursor를 복호화하는 메소드를 제공해주지 않다 보니 암호화해서 얻은 cursor를 복호화하기 위해 많은 시간을 투자해야 했습니다. 그리고 직접 사용해보니 그렇게 편한 라이브러리도 아니었습니다... 요번에는 한번 사용해보고 싶어서 적용해보았지만 다음부터는 직접 구현하는 방법을 선택할 것 같습니다.
어쨌든 위의 코드에서 똑같이 자잘 자잘한 조건을 제외하고 관계형 데이터베이스로 옮기면 다음의 쿼리가 완성됩니다.
SELECT
h.historyId as 'ID',
h.type as '거래종류',
h.amount as '사용 금액',
h.historyBalance as '거래후 잔액',
h.briefs as '적요',
h.createdAt as '거래일시'
FROM
history h,
account a
where
a.accountNum = h.accountNum
AND h.historyId < cursor
order by h.historyId DESC
limit 10;
limit offset pagination을 한 것과 마찬가지로 상위 10행과 하위 10행의 데이터를 가져와서 몇 ms가 걸리는지 비교해보도록 하겠습니다. 먼저 상위 10의 데이터를 가져와 보겠습니다. cursor에는 해당 id값이 담겨있습니다. (다만, 실제로 적용할 때는 맨 처음 pagination을 했을 때 기준이 되는 cursor값은 백엔드에서 알려주기 전까지 클라이언트는 알 수가 없습니다.)
확인 결과 최상위 10행을 가져오는 데에 13ms 정도의 시간이 걸렸습니다.

이번에는 최하위 10행과 다른 위치의 10행을 가져와 보도록 하겠습니다. 놀랍게도 각각 15ms, 14ms 정도의 시간이 걸렸습니다.


이처럼 cursor pagination기법이 limit offset pagination보다 빠른 이유는 where 조건절에 고유한 값을 전달함으로써 다른 행들을 건너뛸 수가 있기 때문입니다. 보통 관계형 데이터베이스의 PK에는 기본적으로 index가 걸려있기 때문에 이러한 작업이 가능합니다. 물론 PK가 아니어도 cursor로 사용할 수 있으나 반드시 고유한 값을 전달해줘야 사용할 수 있습니다. 그리고 limit offset pagination기법은 클라이언트에서 pageNum을 전달해주면 페이징을 해줄 수 있게 작업할 수 있으나 cursor pagination기법은 클라이언트에서 cursor값을 전달해줘야 페이징을 할 수 있습니다. 그래서 limit offset pagination 방법에 비해 query param url이 조금 복잡합니다.
👩💻 반성점 OR 다음 프로젝트부터 고치고 싶은 것
저희 팀은 TypeOrm을 사용하여 페이지의 성능 향상에 성공한 듯 보이지만 typeorm-cursor-pagination의 라이브러리를 잘못 사용하는 바람에 조금 아쉬운 성능의 결과를 보여주게 되었습니다. 코드도 가독성이 별로 좋지는 않았고요. 하지만 요번 기회로 TypeOrm Seeding을 사용해 3만 여건의 데이터를 넣어 직접 pagination 성능 향상을 해볼 수 있어서 좋았고, 새로운 지식을 얻을 수 있었던 뜻깊은 프로젝트로 남았습니다. 다음번에는 라이브러리를 사용하지 않고 직접 구현하는 것을 목표로 pagination을 해보도록 하겠습니다.
'프리온보딩 백엔드 > TIL(Today I Learned)' 카테고리의 다른 글
| [Assignment 6] Deer(디어) TIL (3) | 2021.11.24 |
|---|---|
| [Assignment 5] Humanscape(휴먼스케이프) TIL (0) | 2021.11.18 |
| [Assignment 3] RED BRICK(레드브릭) TIL (0) | 2021.11.11 |
| [Assignment 2] MAPIA COMPANY(마피아 컴퍼니) TIL (0) | 2021.11.07 |
| [Assignment 1.5] 어쩌다 개발이 재밌어진 건에 대하여 (2) | 2021.11.06 |



